MIT6.824Lab
Lab1
MapReduce的工作流程
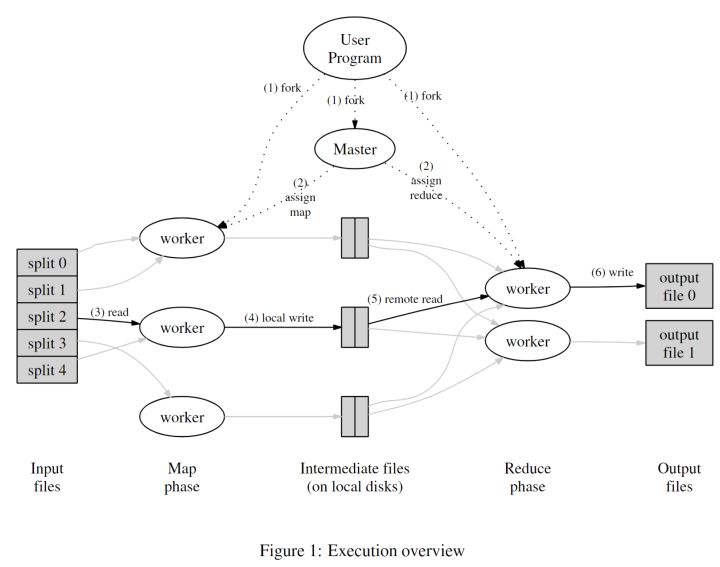
整个Lab1的目标基本上就是实现这张图上的功能。
在已有的代码里已经提供好了一些map和reduce方法,我们要做的就是通过一个Coordinator来给多个Worker分配任务,每个Worker执行一个map或reduce任务。
那么该如何在Coordinator和Worker之间进行信息的交流?这里有很多种方法,因为这是在本地执行,所以可以利用共享内存、管道等进程间通信方式来实现。而对于跨机器的进程,可以使用RPC来远程调用方法,恰好Lab里提供了RPC的使用方法。
大致思路如下:
Coordinator里有GetTask和FinishedTask方法,Worker会一直循环通过RPC调用这两个方法来获取任务和通知任务完成,根据获取到的不同任务类型执行不同方法,直到所有任务做完。
Worker里有两个主要函数performMap和performReduce分别用来执行map和reduce任务。
由于需要知道任务的一些信息,所以我需要在GetTask和FinishedTask的参数类型中进行定义。
1 | // Worker通过调用GetTask方法向Coordinator获取任务 |
在go里RPC注册函数的规则是
1 | func (t *Type) Method(args interface{}, reply interface{}) error {...} |
所以两个方法大体如下
1 | func (c *Coordinator) GetTask(args *GetTaskArgs, reply *GetTaskReply) error { |
假如此时有一个Worker向Coordinator获取任务,Coordinator会遍历所有任务,当有任务未开始或者执行超时,Coordinator就会向当前这个Worker发布任务。
当Worker执行完该任务,它会通知Coordinator该任务已完成,并打上标记。
对于Coordinator,就需要维护所有任务的信息,它的定义如下
1 | type Coordinator struct { |
Lab中还有一些小细节,比如map任务执行完后数据存放位置。根据Lab的提示,可以将所有这些中间文件以"mr-X-Y"的形式命名,存为临时文件,X表示第几个map任务,Y表示第几个reduce任务。而reduce执行完后将输出文件以"mr-out-X"的形式命名,X表示第几个reduce任务。
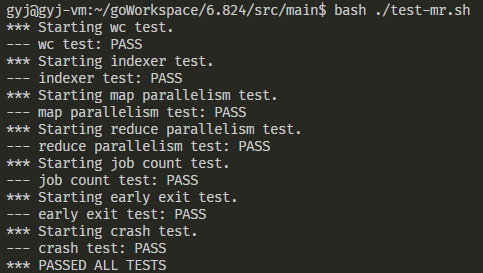
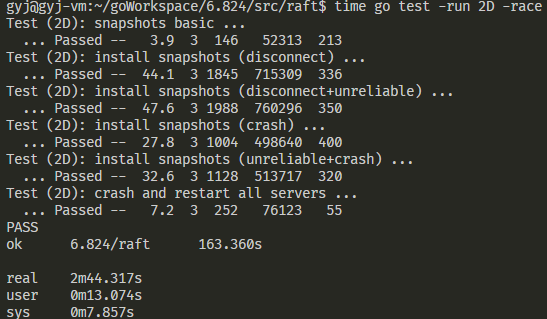
贴一张完成后并通过所有测试的结果
Lab2
一些参考资料:
Raft官网:Raft Consensus Algorithm
Raft可视化网站:Raft (thesecretlivesofdata.com)
Lab2A
Lab2A需要实现的是Raft启动时的Leader Election,也就是选举阶段。
目标
在2A的测试代码中,主要分为以下几个测试目标:
- 正常情况下能否选出一个leader以及保持一段时间后要保证leader及term不变
- 将leader离线,查看剩下的server能否选出新的leader,并且旧的leader恢复正常后不影响新leader
- 断开半数以上的服务器包括leader,剩下的server不会选举出新leader
分析
根据论文中的描述,每个server有三个状态:Follower、Candidate、Leader,初始时都为Follower。server会有一个随机的选举超时时间,如果当一个server选举超时,那么他就会从Follower转变成Candidate,并将自己的Term+1,也就是表明开启一个新的任期。只有当Candidate收到超过半数的投票,它才会变成Leader。
因为2A仅涉及选举过程,所以我们只考虑server的以下几个状态
1 | type Raft struct { |
为了检测选举超时,我们可以开启一个线程,通过不断死循环,每次循环中会sleep随机时间(随机时间使得能够在一个比较快的时间内选出Leader),接着让该server中的最近收到心跳检测的时间和sleep前保存的一个时间相比,如果途中没收到任何消息,该server就进行选举。
该线程大致如下
1 | func (rf* Raft) ticker() { |
在选举过程中,首先将server转变成Candidate,只要是转变成Candidate就说明要开启新任期,那么currentTerm就会+1,votedFor会投给自己,同时刷新超时时间。然后去遍历每一个server,给他们发送投票请求。只要超过半数投票,就会转换成Leader,并通知其他server不需要选举了。
而对于Follower,假如我当前收到了一个投票请求,只有当请求的Candidate任期不小于我,且该任期内没有投过票,我才会给它投票。如果我的任期比它大,那么Candidate会转变成Follower并将任期更新成我的任期,同时重置其他状态,退出选举。
索取投票流程大致如下
1 | func (rf *Raft) StartElection() { |
因为Leader会定时发送心跳检测,我们可以将心跳检测另开一个线程,类似于刚刚的ticker()。需要注意的是发送心跳检测的时间间隔必须远小于投票超时时间,否则会发生一个Leader还没发送心跳检测就会产生新的Candidate开启选举,当前这个Leader就失效了。
对于断线后重连的Leader,因为在Raft协议中只有最大的Term才是真Leader,所以当真Leader发送心跳检测时,如果发现有Term比我小的,那么就会将它Term更新并置为Follower。还有一种情况是旧Leader先发送了心跳检测,那么如果server收到后发现发送者的Term比该server小,server会返回一个false。
因为代码中涉及到很多多线程,所以在读写数据时最好都要加上锁,在我的代码中全部是使用的它已经给定的互斥锁,没有考虑锁的粒度,因此可能会比较慢。在不考虑各种优化的情况下成功通过了2A的测试。
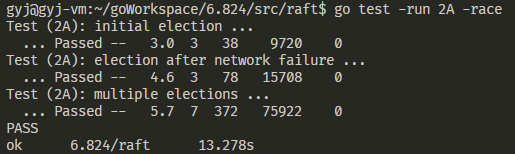
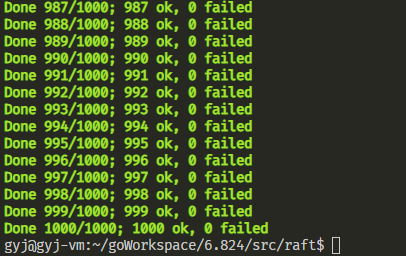
Lab2B
lab2B需要实现Raft的日志同步阶段,细节非常的多。
目标
Lab2B主要有8个测试(整理自2020 Spring 6.824 Lab2B: Raft Log Replication笔记 - 知乎 (zhihu.com) ):
- 简单提交一个log,检查各个Raft server关于该log有没有达成协议
- 检查在没有断联的情况下有没有重发、多发
- 测试少数节点失败重连时的系统情况
- 测试多数节点失败重连时的系统情况
- 检查并发向Raft准备同步的日志里提交的情况
- 老leader断联后收到一堆log,新leader也收到一堆log,重连老leader,检查是否正常
- 检查日志同步能力,不断断联不同leader,再一下子连接回来,考察复杂网络情况下Raft能不能保证数据同步稳定性
- 检验整个集群的commit需要的时间和RPC次数,以及没网的情况下leader和term是否有变化
分析
首先我们得要改进Lab2A的选举,因为有了日志,leader在获取选票时要把另外两个参数考虑进去,所以最终的RequestVoteArgs为
1 | type RequestVoteArgs struct { |
收到该RPC请求的server也需要多比较LastLogIndex和LastLogTerm来判断是否可以给该Candidate投票。
在Lab2A的基础上,首先比较的是自己最后一个log的Term和选举人的Term,如果比我大或者一样大且最后一个log的索引号不小于我,我才会给他投票,其他情况均不投票。
然后需要改进的是leader发送心跳检测的内容。一个是在Raft这个类中多了几个变量
1 | type Raft struct { |
另外,在之前我们只考虑了无log发送的情况,现在多了log后,AppendEntryArgs为
1 | type AppendEntryArgs struct { |
LeaderCommit参数主要是为了让server的commitIndex和leader进行同步,说明这之前的log已经被大多数server复制,已经可以准备提交到上层去执行。
1 | func (rf *Raft) AppendEntry { |
PrevLogIndex为leader的nextIndex[server]-1,PrevLogTerm是该index上日志的Term。如果说两个参数中有任意一个没和server的对上,server会返回一个false,leader就会将nextIndex[server]–,直到log为同一个term以及index相同。这里有个优化,就是在返回的参数中给定server的冲突的term第一次出现的下标,只有加上这个优化才能通过第七个测试,虽然论文上说该优化在实际中用处不大。
1 | func (rf *Raft) AppendEntry { |
在leader的心跳检测方法中就需要加上对应的措施来应对不匹配
1 | func (rf *Raft) sendHeartbeat { |
2B主要的坑点是多了很多的index或term这样的参数,判断时需要分成好几类,很容易出错,以及在强化2A选举过程时有很多代码进行了重构,导致有一些细节丢失,2B的第七个测试老是出现选举不出leader的问题,到最后才发现是在某处忘记将身份改成follower。
基本上2B的代码都是照着论文中的Figure2的描述完成的,同时参考了网上很多份讲解,才彻底搞懂了几个参数之间的关系。主要的时间还是花费在debug上,有时候可能会因为数据忘记上锁导致data race。
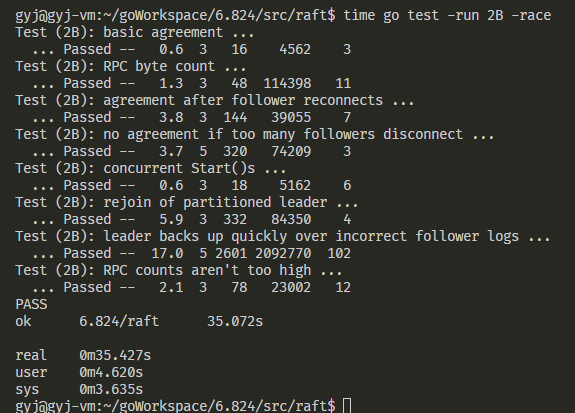
Lab2C
lab2C需要实现Raft的可持久化阶段。
目标
整理自(MIT 6.824-Lab 2 学习记录_LLLSoul的博客-CSDN博客 )
- 节点宕机恢复验证持久化正确性
- 验证网络分区故障的情况下持久化数据的正确性
- 验证Leader宕机能否正确回复日志(除了所有类型节点都要在append、vote那里要持久化,Leader还有其它的地方需要持久化)
- 测试paper中图8的错误情况,避免直接提交以前term的日志,其实只要知道怎么做就行了,在apply前加个判断term是否为最新的条件
- 模拟不可靠网络的情况
- 基于不可靠网络的图8测试
- 并发测试
分析
先要完成persist和readPersist两个函数的内容,这两部分比较简单,框架中已经给了足够的提示。
难的主要是在测试,虽然2B测了上百次基本上能够通过,但是到了2C中,Figure 8和Figure 8(unreliable)这两个测试刚开始一直会出现apply error或者是fail to agreement,在网上找相关失败原因后发现可能的原因是集群内同步效率低,或者是一些细节没处理好。
接着在代码中发现没有处理Figure 8的情况,刚开始之去判断了大多数节点的commitIndex是否大于leader的commitIndex,没有比较最后一个log的term和currentTerm是否相同,这就或导致Figure 8中的情况发生。也就是说leader重连后需要先收到一个最新的log才能对之前的log进行提交。
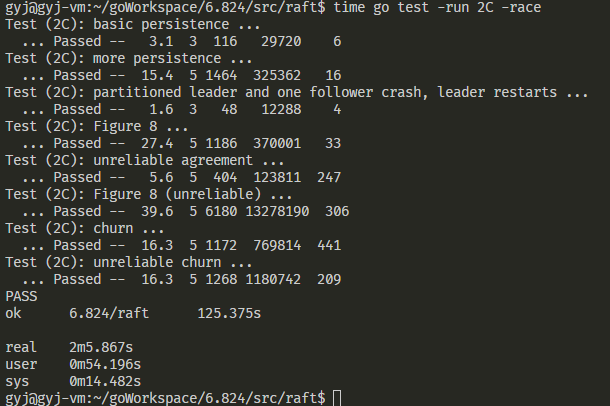
Lab2D
lab2D需要实现Raft的日志压缩阶段。
目标
本阶段的目标主要是测试日志压缩,类似于2B和2C,会模拟很多网络故障或机器故障,然后在此基础上测试日志是否能够同步,并需要在到达一定时候修剪日志。
分析
之所以需要压缩日志是因为不可能让服务器一直让log添加下去,否则迟早有一天会爆满。
在最后一个阶段,需要修改一些之前的代码,比如一些下标。在前几个lab中,我都是直接用从0开始的下标当作真实下标来用,但加入日志压缩后,会出现下标和日志内容对不上,因为前面的日志已经被我删掉了,我得重新计算日志的下标。因为需要保留快照的信息,也就是lastIncludedIndex和lastIncludedTerm,可以让第0个日志为快照的内容(之前第0个日志一直为空日志)。并在每个日志中加上Index信息,这样子我们就可以用Index-lastIncludedIndex来计算下标。
本阶段需要实现Snapshot()和一个InstallSnapshot RPC。Snapshot()是上层对Raft的调用,如果Raft收到一个Snapshot(),就说明上层需要压缩日志,所以部分的代码不是很难
1 | func (rf *Raft) Snapshot(index int, snapshot []byte) { |
对于InstallSnapshot RPC,我们需要定义参数和返回参数,在论文中已经给出
1 | type InstallSnapshotArgs struct { |
而InstallSnapshot()函数类似与发送心跳的AppendEntry(),是leader对folloer调用,
1 | func (rf *Raft) InstallSnapshot(args *InstallSnapshotArgs, reply *InstallSnapshotReply) { |
在leader的发送心跳前还需要判断follower的nextIndex是否大于我的lastIncludedIndex,如果大于,就发送普通的心跳检测,否则发送快照。
1 | func (rf *Raft) sendHeartbeat() { |
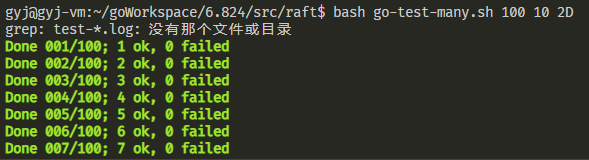
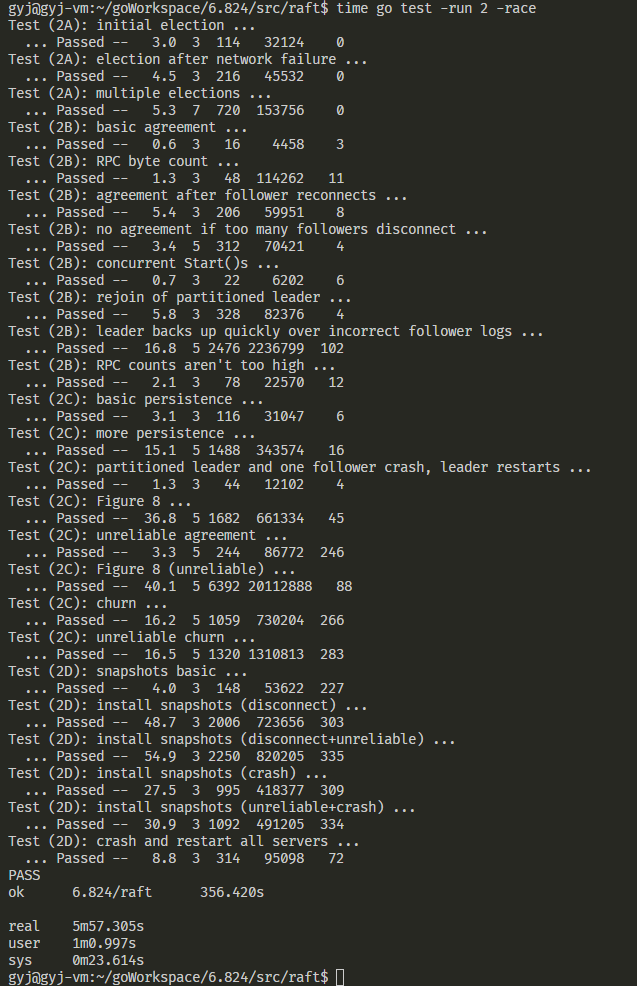
最后是一张lab2总的测试结果
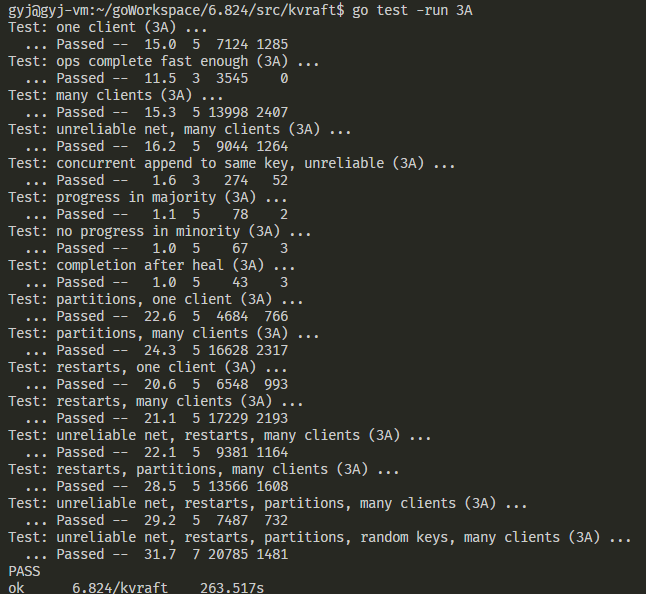
Lab3
Lab3A
在Lab2中已经实现了Raft,Lab3主要是在Raft的基础上实现一个具有容错机制的存储服务器,需要满足线性一致性。Raft为上层保证了共识性,但对于客户端和服务端来说还不是线性一致,所以Lab3中主要就是要在客户端和服务端实现线性一致性的语义。
目标
需要完成client和server端的逻辑。
在测试中,会让client快速发送指令给server,server需要对这些指令实现线性一致。
从一个client到多个client,以及模拟了网络损坏的情况,或者是server宕机的情况。
分析
比较容易完成的是client端的代码,作为客户端,我只需要发送我的命令给server,如果失败了重复发送直到成功。
因为client是通过RPC发送的,所以先要对RPC的两个参数进行定义
1 | type PutAppendArgs struct { |
然后是client的PutAppend()方法(Get()方法同理)
1 | func (ck *Clerk) PutAppend(key string, value string, op string) { |
在server中,会收到来自client端的RPC请求,server需要将请求的操作通过Raft的Start()方法交给Raft层,并等待Raft层达成共识,接着Raft层会通过applyCh管道,发送已经达成一致的操作,最后server才能够执行该条操作。
这里参考了MIT 6.824: Distributed Systems- 实现Raft Lab3A | 鱼儿的博客 (yuerblog.cc) 的做法。
server首先保存关于该操作的上下文,并给每个操作一个管道,主要是为了能够快速处理多个操作。然后server利用select等待操作的一致,最后将该上下文删除并返回结果,所以大致如下
1 | func (kv *KVServer) PutAppend(args *PutAppendArgs, reply *PutAppendReply) { |
因为raft层随时会提交操作,所以server需要另开一个线程监听applyCh,一但有操作提交,server就可以开始判断该操作是否过时之类的,如果都合法,则执行该操作,然后给reqMap[index]中的管道发送信息,告诉他该操作已经执行完毕。
apply大致如下
1 | func (kv *KVServer) apply() { |
还需要注意的一点是,Lab3A中有个测试是ops complete fast enough。在这个测试中,Test会发送1000个PutAppend请求,要求请求速度快于33.3333ms/op。我们需要对Raft层进行一些修改,当Raft的Start()方法一收到来自server的command,就要立即对其他follower发送心跳检测,以便快速达到一致性,可能还需要适当调慢心跳检测发送的速度,因为如果发送速度太快,可能会导致多个线程中锁的争抢,从而拖慢整个程序的速度。如果还是速度慢,可以试试运行时不加-race编译选项。
 微信
微信 支付宝
支付宝



