CMU15-445 Project
该课程主要实现一个单机数据库,支持基本的SQL操作,并且实现了并发控制。每年秋季会出新的project,内容可能会有些区别,像2020年需要实现一个B+ Tree,而2021年实现的是Hash Index。对于外校的人,课程提供了project的提交网站,有非常大的帮助。
课程主页:CMU 15-445/645 :: Intro to Database Systems (Fall 2021)
Project1
Task1 - LRU REPLACEMENT POLICY
目标
实现一个LRU Replacer,用来跟踪页面使用情况,并采取LRU替换策略。主要跟后面的Buffer Pool配合使用。
实验已经给了LRUReplacer类,主要需要完成三个函数:
bool Victim(frame_id_t *frame_id):删除一个最近最久未使用的页面。void Pin(frame_id_t frame_id):被Pin的frame说明正在被引用,需要将该frame从Replacer中删除。void Unpin(frame_id_t frame_id):当frame的pin_count减为0时调用该函数重新将frame加入Replacer中。size_t Size():当前跟踪的frame数量。
分析
第一个Task没什么难度,无非是用list和unordered_map来维护一个LRU list,可以参考Leetcode上的LRU的题目实现。
由于可能涉及到并发问题,所以需要一个mutex进行资源访问控制。
Task2 - BUFFER POOL MANAGER INSTANCE
目标
实现缓冲池管理器,它负责将获取磁盘中的数据库页面并存储到内存中,每个页面被抽象成了Page类,每个Page对象就是一个内存块,里面还包含了一些信息,比如page_id该对象维护的页面的id,pin_count被引用的数量,is_dirty是否是脏页。
在BufferManagerInstance中有一个page_table,包含的是page_id到frame_id的映射(一般在磁盘中的页称为page,在内存中的页称为frame)。还有free_list,该列表中维护的是未被使用的内存中的页的id。
几个需要实现的函数:
FetchPgImp(page_id):抓取某个磁盘中的页面。UnpinPgImp(page_id, is_dirty):减少一个关于该页的引用。FlushPgImp(page_id):刷新页面,即将页面内容写回磁盘。NewPgImp(page_id):创建一个新的页。DeletePgImp(page_id):删除一个页。FlushAllPagesImpl():刷新所有页面。
分析
一开始,因为所有内存页都还未被使用,所以所有的内存页面id都存在free_list中。
先来看最简单的两个函数,第一个是FlushPgImp,首先判断page_id是否有在内存中的映射,如果没有直接返回false,否则调用disk_manager的WritePage方法将内容写回磁盘。第二个是FlushAllPagesImpl,直接遍历page_table,将所有页面写回磁盘。
NewPgImp是创建新的页面,先判断free_list是否为空,如果不为空,直接从该列表中取一个frame_id,并更新缓存中该Page对象的信息,以及更新page_table中的映射关系。如果为空,那么就得向LRUReplacer索取一个没被引用页面,如果所有页面都被引用,直接返回nullptr,否则会获得一个frame_id,如果是个脏页,要记得将它写回磁盘,然后将该页信息更新为新的信息,同时更新page_table。最后要记得将该page中的pin_count设置为1。
FetchPgImp抓取页面,假如page_table中存在,直接返回该page的地址,将pin_count加1。否则要像NewPgImp一样的步骤,不同的地方在于修改page元信息时,NewPgImp是清空内容,而FetchPgImp是从磁盘中读取并将内容存储到page,这是因为FetchPgImp是抓取已存在的页面。
DeletePgImp删除一个页面,假如本身就不存在,返回true。否则如果关于该页的引用不为0,返回false。删除页前需要将脏页写回磁盘,将page的page_id设为INVALID_PAGE_ID,page_table需要删除关于该页的映射,free_list重新加入一个frame_id,也就是该页原先映射的frame。
UnpinPgImp释放一个该页的引用,假如不存在该页,直接返回,如果减完后page的pin_count为0,需要调用lru中的Unpin,即将它插入lru列表,以供之后的页面替换。
在该Task中将数据写回磁盘的时机有很多种方式,不同的方式影响也不同,但没有好坏之分,必须看实际情况。我采用的是在每次页面将要被踢出内存时进行写回,即延迟写回,一个好处是减少了IO开销。
Task3 - PARALLEL BUFFER POOL MANAGER
目标
因为单个缓存池管理器可能会在并发时导致多个线程争抢同一把锁从而降低运行效率,所以需要设计一个并行的缓冲池,里面有多个单一缓冲池,每个缓冲池有自己的锁,这样子就可以分担并发时的压力。
分析
这部分内容基本上就是调用Task2中的函数,只是需要在调用前获取page_id属于的那个缓冲池管理器。
稍有不同的是NewPgImp,它会轮询每个缓冲池,直到某个缓冲池新建成功时才会返回。
Project2
Task1 - PAGE LAYOUTS
目标
Task1需要实现关于拓展哈希的directory和bucket部分,不了解的话可以先学习一下拓展哈希。
分析
先来看directory,在directory的有文件中提供了以下几个对象:
1 | page_id_t page_id_; // directory本身所在的页号 |
这里需要实现的函数没有特别复杂的。稍微讲讲几个注意点,在IncrGlobalDepth中,需要记得将拓展后的local_depths和bucket_page_ids进行更新每一个bucekt会分裂成两bucekt,他们都指向原来的depth和page_id。
在CanShrink中,只有当所有的local_depth都严格比global_depth小,才会返回true,即进型收缩。
再来看看bucket部分,类中提供了的对象:
1 | char occupied_[(BUCKET_ARRAY_SIZE - 1) / 8 + 1]; // 第i个位置表示array_[i]是否有被占据 |
可以注意到上面两个数组都是char型数组,也就是说每个位置都是8位bit。bucket类中的很多函数主要是做一些运算找到给定的id所在的位置。比如IsOccupied函数:
1 | template <typename KeyType, typename ValueType, typename KeyComparator> |
bucket_idx / 8可以获得所在数组中的位置,bucket_idx % 8可以获得所在的哪一bit上。其他也有几个类似的函数,就不再展开。
在GetValue中可以先遍历整个数组,如果遇到readble不为0的位置,再去遍历这8个bit,遇到key相同的就将value加入到result结果中。当然,可以更暴力的直接扫描每一个bit,类似于
1 | template <typename KeyType, typename ValueType, typename KeyComparator> |
Insert和Remove都与GetValue类似,可以直接遍历每一位,然后进行occupied和readable状态的判断。
Task2 - HASH TABLE IMPLEMENTATION
目标
实现拓展哈希的逻辑部分,可以支持插入、删除、查找。细节上,需要实现bucket的分割、合并,目录的拓展、收缩。
主要有以下几个函数:
Insert(Transaction *transaction, const KeyType &key, const ValueType &value):插入一对键值对。
Remove(Transaction *transaction, const KeyType &key, const ValueType &value):删除一对键值对。
GetValue(Transaction *transaction, const KeyType &key, std::vector<ValueType> *result):获取key的所有对应的value。
KeyToDirectoryIndex(KeyType key, HashTableDirectoryPage *dir_page):根据key获取directory下标。
KeyToPageId(KeyType key, HashTableDirectoryPage *dir_page):根据key获取所在的桶的page_id。
FetchDirectoryPage():抓取目录页面。
FetchBucketPage(page_id_t bucket_page_id):抓取某一个桶页面。
SplitInsert(Transaction *transaction, const KeyType &key, const ValueType &value):和Insert配合使用,当需要拓展时,Insert会调用SplitInsert。
Merge(Transaction *transaction, const KeyType &key, const ValueType &value):收缩整个拓展哈希表。
分析
首先是构造函数,需要先新建一个页面给目录,并且有一个bucket,global和local的depth都为0,具体如下
1 | // 一开始directory的global_depth为0,只有一个bucket |
在C++中reinterpret_cast作用是强制转型,准确的说是强制将某一块连续的二进制解释为目标类型。GetData()会得到一个char *类型的返回值,也就是Page类中的一个char数组,调用reinterpret_cast后,就会将这块内存解释成HashTableDirectoryPage类型。
然后是一些帮助函数,这些函数比较简单,基本上就是一行代码调用其他类的函数,比如KeyToDirectoryIndex,该函数需要将hash值与directory中的global_depth作&运算
1 | template <typename KeyType, typename ValueType, typename KeyComparator> |
在抓取页面函数中,也要进行reinterpret_cast转型,和构造函数中的类似。
重点是接下来几个函数。
GetValue,刚开始需要给目录上读锁,在获取到相应bucket所在的page后,需要给该page上读锁,然后执行bucket的GetValue函数获取结果
1 | // 目录上读锁 |
对于Insert函数,同样是先对目录上读锁,获取相应bucket页面,如果该页面已经存满了,说明需要进行分裂,此时就需要调用SplitInsert函数,否则直接插入。
而SplitInsert函数一开始需要给目录上写锁,因为拓展需要修改目录的一些信息,记录下旧的bucket的id信息,在拓展前还需要判断一下旧的bucket是否依然是空的,因为之前Insert调用Split的时候解锁了,中途可能被其他函数调用。确认依然是满的,就要开始进行扩容,增大global_depth和local_depth,先判断是否已满,满的状态也就无法扩容只能返回false
1 | // 最多只有512个桶 |
然后先增加global_depth,再增加local_depth,这里其实有很多种实现方式,顺序也不是固定的,主要看具体实现,总之能达到拓展哈希目的即可
1 | // 如果local_depth与glocal_depth相等需要增加global_depth |
接着创建image_page,也就是之前old_page分裂出来的另一个兄弟page,它的local_depth设置和old_page一样。然后要对old_page的内容进行rehash,不然old_page还是满的,无法满足插入要求
1 | for (uint32_t i = 0; i < BUCKET_ARRAY_SIZE; i++) { |
最后要设置目录的bucket_page_ids和local_depth这两个数组内容,除了新增的imag_page指向其他page,其他新增的bucket都是只想原先分裂出来的那个bucket。接着在调用一遍Insert函数即可。
Remove函数要和Merge函数配合使用,类似插入操作,如果在移除后调用CanShrink发现返回true,那么就可以进行收缩,收缩流程基本就是SplitInsert反着来,也就是所有指向空的page的bucket_id要指向兄弟page,然后设置目录的内容。
Task3 - CONCURRENCY CONTROL
目标
刚刚都是假设所有操作都是再单线程上完成的,现在加入多线程后,要再每个函数中加上相应的读写锁。
分析
在Task2中已经有分析道加锁。只有当对目录进行修改时才需要加目录的写锁,对bucket进行修改时才需要加bucket的写锁,其他情况一律加读锁即可。
Project3
Task1 - EXECUTORS
目标
实现基础的SQL操作。将使用迭代器查询处理模型(火山模型),模型中的每个查询计划都要实现一个Init函数进行初始化,一个Next函数,当DBMS调度器调用执行一个Next函数时,执行器就返回单个元组,调度器会循环调用Next函数,并逐个处理他们。
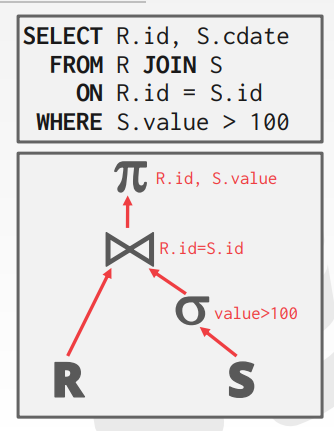
这是课件中的一张图,很形象的展示了一个简单的执行模型。
分析
这部分内容很多,类的关系也很复杂,先来缕清各个类之间的关系。
首先可以看一下关于excutor的单元测试
1 | // SELECT col_a, col_b FROM test_1 WHERE col_a < 500 |
这是SELECT部分的单元测试,可以看到先要构造一个输出表的格式,通过MakeColumnValueExpression构造了两个关于col_a和col_b的列表达式,因为存在WHERE子语句,所以还需要通过MakeConstantValueExpression构造一个常数表达式,将col_a和const500两个表达式一起合并成一个为比较谓词表达式predicate,最后是构造一个SELECT的执行计划,也就是plan。在Execute函数中,通过抽象工厂创建了一个执行器,先是调用执行计器中的Init函数进行初始化,然后不断循环执行Next函数一个一个的获取结果。
1 | bool Execute(const AbstractPlanNode *plan, std::vector<Tuple> *result_set, Transaction *txn, ExecutorContext *exec_ctx) { |
我们需要实现的SeqScanExecutor就只需要完成Init和Next这两个函数,因为火山模型是通过一个一个去取出结果,所以需要定义一个迭代器,刚开始指向表最开始的元组,每次调用Next时我就要去循环直到找到符合predicate条件的结果后返回,则下一次是从下一个位置开始继续循环判断,具体如下
1 | bool SeqScanExecutor::Next(Tuple *tuple, RID *rid) { |
在InsertExecutor中,与SeqScanExecutor有几点不同,一个是insert可能有子执行器,比如一个查询语句可能是INSERT INTO ... SELECT ...,此时SELECT就是子执行器,那么在Init和Next中也要调用子类的Init和Next,插入的同时还要更新所有的索引,具体可以看代码
1 | bool InsertExecutor::Next([[maybe_unused]] Tuple *tuple, RID *rid) { |
DeleteExecutor和InsertExecutor两个执行器和INSERT的类似,同样也要注意执行子计划,然后是要记得索引的更新。
接下来看两个JOIN,一个是NestedLoopJoinExecutor,另一个是HashJoinExecutor。
JOIN的执行语句可能类似于SELECT ... FROM [table_name1] JOIN [table_name2] ON t1.attr = t2.attr
前一个比较简单,他在构造时先初始化了两个子执行器,因为JOIN会有两个表,所以必定有两个子执行器,在Init时先调用左执行器的Init,也就是俗称的外表。在调用Next时,需要先判断内表是否为空,如果为空,则调用内表的Init函数,即让内表的指针指向首个元组位置,直到外表的指针也为空时,就可以返回false了。所以第一个JOIN其实就是个很简单的双重循环,这里其实也可以先调用右执行器的Init,也就是跟之前相反的操作,但是效率可能会没有之前高,具体原因可以参考《数据库系统概念》,里面有讲到如何选择遍历的顺序能够进行比较高效的JOIN操作。
对于第二个JOIN,实际上就是用到了hash表,将其中一个表要比较的属性存到hash表中,然后遍历另一个表,当遇到hash值相同的就将他们加入到结果中。
接着是AggregationExecutor,这里就是数据库的一些聚合函数,需要实现COUNT、SUM、MIN、MAX,当然还要支持GROUP BY以及HAVING。实现聚合的一个策略就是使用哈希,它已经提供了一个封装好的哈希表SimpleAggregationHashTable,里面有个GenerateInitialAggregateValue按照聚合类型进行初始化,还有一个CombineAggregateValues函数,它的作用是对于输入的值进行一个计算,假入聚合类型是COUNT,那么它会在该聚合的结果上加1,其他类似。在Init函数里就是不断计算聚合的结果,将相同GROUP BY的结果放一起,在Next中就是去遍历这个哈希表,然后构造输出的结果,返回给上一层。具体代码大致如下
1 | void AggregationExecutor::Init() { |
LimitExecutor就比较简单了,直接在类中添加一个count计数,当count超过limit后直接返回false即可。
最后一个是DistinctExecutor,既然是唯一,那么肯定也是要用到哈希表的,同样的,在该类中也要用哈希表进行结果存储,可以直接利用STL中的unordered_map,不需要用Task2的拓展哈希,并且需要像Aggregation一样,实现关于key的hash,模仿它写了一个
1 | struct DistinctKey { |
每次上面调用Next就需要判断key是否已经存在,如果不存在就将它加入哈希表,并返回该值。
Project4
Task1 - LOCK MANAGER
目标
在DBMS中将使用一个锁管理器来控制事务访问数据。需要实现三种隔离级别,分别是READ_UNCOMMITED、READ_COMMITTED、REPEATABLE_READ,在Transaction类中提供了事务的上下文,包括隔离属性级别,锁的信息等。
分析
这一部分就是完成LockManager这个类的内容。LockManager类中还有两个嵌套类,LockRequest和LockRequestQueue
1 | class LockRequest { |
锁管理器过程针对锁请求消息返回授予消息,或者要求事务回滚的消息。它为已加锁的每个数据项维护一个链表,每一个请求为链表中的一条记录,按请求到达顺序排序。
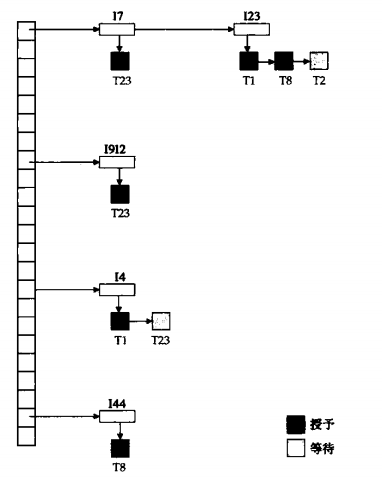
以下是锁管理器的处理过程:
- 当一条请求到达时,如果相应数据项的链表存在,就在该链表尾部增加一条记录;否则,新建一个链表并添加该条记录。
- 当锁管理器收到一个事务的解锁消息时,它将与该事务相应的数据项链表中的记录删除,然后检查随后的记录,如果有,就看该记录能否被授权,如果能,锁管理器就授权该请求并处理之后的记录。
- 如果一个事务中止,锁管理器删除该事务产生的正在等待的所有加锁请求。
再来了解一下集中事务隔离级别(由低到高):
- 未提交读(read uncommitted):只允许读取未提交数据。该级别下不需要加共享锁,只用加排他锁。
- 已提交读(read committed):只允许读取已提交数据。两种锁都需要加,并且读完就释放。
- 可重复读(repeatable read):只允许读取已提交数据,并且在一个事务的两次读取一个数据项期间,其他事务不能更新该数据。两种所都要加,且要实现采用严格两阶段锁协议。
- 可串行化(serializatble):保证可串行化调度。
然后是2PL,也就是两阶段锁协议,这是保证可串行化的一个协议,它将分为两个阶段,一个是growing,只允许获取锁,另一个是shirinking,只允许释放锁。
Task2 - DEADLOCK PREVENTION
目标
当发生死锁时,锁管理器应该使用一些算法来决定暂停哪些事务。
分析
在书中提到了利用时间戳的两种不同死锁预防机制:
wait-die:基于非抢占技术。当事务申请的数据项当前被持有,仅当的时间戳小于的时间戳(即比老)时,允许等待。否则,回滚。
wound-wait:基于抢占技术。当事务申请的数据项当前被持有,仅当的时间戳大于的时间戳(即比年轻)时,允许等待。否则回滚。
这里我们需要实现的是关于wound-wait的死锁预防机制,具体实现就是,当我要加的这个锁之前有比我年轻(事务编号更大)的锁,并且与锁之间不相容,那么就将年轻的事务进行回滚,否则我就等待,直到前面的锁都释放。
Task3 - CONCURRENT QUERY EXECUTION
目标
在并发查询的时候,执行器需要适当获取释放锁,以达到指定的隔离级别,需要向project3中的一些执行器的Next方法中添加一些语句。
分析
这部分比较简单,就是在之前的基础上在project3的函数中加些判断,比如在SeqScanExecutor中,只要隔离级别不是RU,那么就需要加共享锁
1 | if (lkm != nullptr && txn->GetIsolationLevel() != IsolationLevel::READ_UNCOMMITTED) { |
当隔离级别为RC时才需要释放这把共享锁
1 | if (lkm != nullptr && txn->GetIsolationLevel() == IsolationLevel::READ_COMMITTED) { |
其他几个同理。
 微信
微信 支付宝
支付宝



